新闻动态
你的位置: 开云(中国)kaiyun体育网址登录入口 > 新闻动态 >

开首:机器之心Pro
AIxiv专栏是机器之心发布学术、时期内容的栏目。往常数年,机器之心AIxiv专栏继承报谈了2000多篇内容,遮盖全球各大高校与企业的顶级实验室,有用促进了学术相似与传播。要是您有优秀的责任想要共享,宽饶投稿或者连接报谈。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
Maitrix.org 是由 UC San Diego, John Hopkins University, CMU, MBZUAI 等学术机构学者构成的开源组织,戮力于于发展妄言语模子 (LLM)、天下模子 (World Model)、智能体模子 (Agent Model) 的时期以构建 AI 驱动的执行。Maitrix.org 此前得胜开荒了 Pandora 视频-话语天下模子、LLM Reasoners,以及 MMToM-QA 评测(ACL 2024 Outstanding Paper Award)。
商酌者们已经并不息构建了屡见不鲜的大规模话语模子(LLM),这些模子的各项才气(如推理和生成)也越来越强。因此,在种种的应用场景中对其进行性能基准测试已成为了一项重要挑战。现在最受宽饶的基准测试是 Chatbot Arena,它通过收罗用户对模子输出的偏好来对 LLM 进行轮廓排名。可是,跟着 LLM 渐渐落地于盛大应用场景,不管是针对工业分娩宗旨,照旧科学场景扶持需求,评估 LLM 在精细化维度上的才气都是至关遑急的,举例:
数学过甚挑升分支领域,如代数、几何、概率和微积分。不同类型的推理才气,举例标识推理、类比推理、反事实推理和社会推理。不同编程话语的编码才气,如 Python、C++、JavaScript 和 SQL。各式科学领域,如物理学、生物学和化学。以及任何与开荒者骨子应用相干的具体问题。
如斯大规模且精细化(致使定制化)的评估关于依赖于东谈主寰球包的 Chatbot Arena 或访佛的基准测试来说是一大挑战 —— 在成百上千个维度上为数千对模子(或数万对模子)收罗富余的用户投票是不切骨子的。此外,由于东谈主类查询和投票经由存在噪声以及个东谈主主不雅身分,评估死心时时难以复现。
最近,商酌者们还探索了其他的自动评估决策,通过礼聘一个(或几个)“最强” 模子(往往是 GPT-4)动作评委来评估通盘其他模子。可是,评委模子可能存在偏见,举例更倾向于礼聘与其本身作风相似的输出。基于这种评估进行模子优化可能会导致通盘模子过度拟合 GPT-4 的偏见。
为了联结这两种决策的上风,通落伍骗 “群体智能”(Chatbot Arena 依赖于东谈主群灵敏)来终了改革经且更少偏见的评估,同期使该经由自动化且可扩张到多维度才气比较,Maitrix.org 发布了 Decentralized Arena。

原文地址: https://de-arena.maitrix.orgLeaderboards: https://huggingface.co/spaces/LLM360/de-arena
图 1 展示了这些基准测试范式之间的主要区别。Decentralized Arena 的核感情念是期骗通盘 LLM 的集体智能进行相互评估和比较。这造成了一个去中心化、民主化的系统,在该系统中,通盘被评估的 LLM 同期亦然粗略评估其他模子的评审者,与依赖于中心化的 “巨擘” 模子动作评审比较,Decentralized Arena 粗略终了更自制的排名。
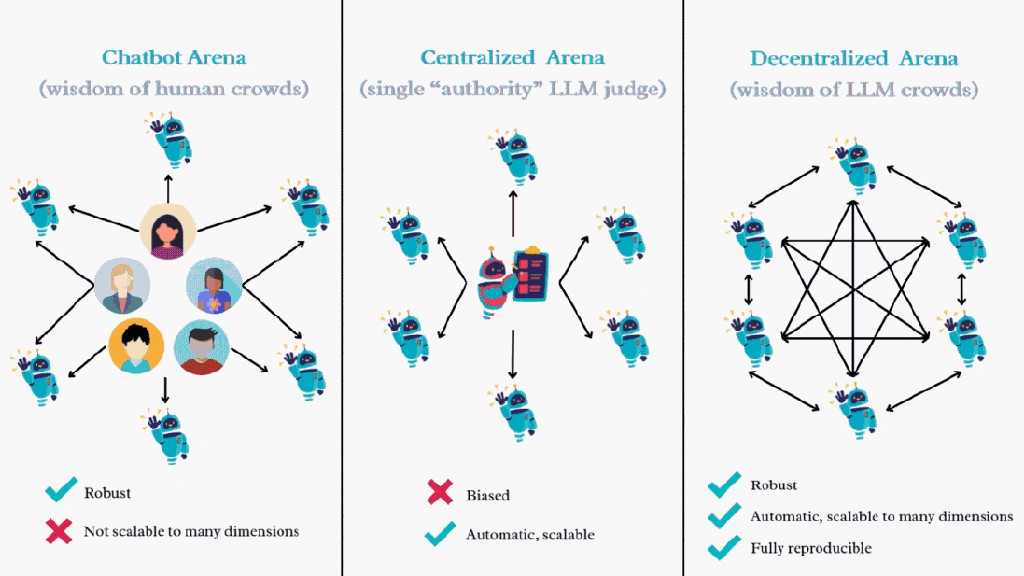
图 1:Open-ended 场景下 LLM 评估的不同范式,Decentralized Arena 联结了两者的优点,即去中心化与自动化。

图 2:Decentralized Arena 与 Chatbot Arena 的 “举座” 排名进展出最强的相干性。
Decentralized Arena 的重要上风包括:
正经且无偏:去中心化幸免了单个或少数评委模子所带来的偏见,况兼回绝易通过过拟合评委模子进行操控。参与竞技场的 LLM 越多,评估越正经(图 4)。此外,Decentralized Arena 在 50 多个模子的 “举座” 维度上与 Chatbot Arena 达到了十分高的相干性(95%,图 2)。自动化、易于扩张且可定制到任何评估维度:由于用户投票的数目有限,Chatbot Arena 只可评估少数维度,而 Decentralized Arena 由于皆备自动化的假想,其粗略扩张到无尽的评估维度,况兼还提供了自动礼聘特定维度问题以终了定制化评估的决策。快速、即时的新模子排名:同样,由于自动化和高效的二分搜索排名算法,Decentralized Arena 粗略即时获取新模子的评估死心,无需恭候数周以收罗用户投票。透明且皆备可复现:通盘算法、终了和输入 / 输出都会公开,使得死心皆备可复现。值得信托:凭借其正经性、与现存东谈主类评估死心的高度一致性、精细的维度分析以及透明度,Decentralized Arena 最终旨在提供一个值得社区信托的基准。
图 3 展示了最终排名榜的截图。商酌团队正在连续添加更多的模子和维度,宽饶来自社区的孝敬和提交!

图 3:Decentralized Arena 排名榜,包括不同维度的排名。
顺次:通过妄言语模子的群体智能进行基准测试
去中心化的见地是通过让通盘 LLM 充任评审,对每一双模子(即决定哪个模子的输出 “到手”,访佛于 Chatbot Arena 中的东谈主类评审)进行投票。一个浅易的作念法是让每个模子对通盘其他模子对进行投票,其复杂度为 O (n^3*k),其中 n 是模子数目,k 是查询数目。当 n 和 k 都很大时,这种顺次的速率会十分慢。因此,商酌团队假想了一种基于增量排名、二分搜索插入和由粗到精迤逦的更高效的顺次。
该商酌从一小组 “种子” 模子(举例 15 个)脱手,期骗上述浅易顺次连忙对它们进行排名。然后,其他模子一个接一个地通过粗筛和精排的关节被增量插入到排名列表中。排名列表中的通盘模子都将动作评审匡助新模子找到其位置。视频 1 阐述了这照旧由。

视频通顺:https://mp.weixin.qq.com/s/4GDQYzbUna_Y1H8Ui5jHIw
视频 1: 演示妄言语模子插入经由。
关节 1: 基于二分搜索插入的和苟且排名。该关节旨在找到新模子在现时排名中的大要位置,其中枢想想是使用二分搜索快速闲静位置范围。在比较新模子与现存模子时,排名中的其他模子将动作评审,该二分搜索的时辰复杂度为 O (k*n*logn)。关节 2: 窗口内精细排名和滑动。为了进一步细化新模子的排名,该商酌将它与排名中相邻的模子进行比较(举例,排名中前后两个模子)。这些相邻的 LLM 时时是最难差异的,因此需要进行更细巧的比较。窗口外的通盘其他模子将动作评审,要是窗口内的比较导致新模子的位置发生变化,则在更新后的窗口内重叠该经由,直到排名褂讪下来。此经由访佛于一个滑动窗口,指点 LLM 群体关注最具混沌性的 LLM 比较对,确保精准排名并最小化策画资本。
在上述排名经由中,该商酌收罗了模子的成对比较死心,然后使用 Bradley-Terry (BT) 顺次来臆度每个模子在排名中的得分。这些得分用于在模子动作评审时赋予它们不同的权重 —— 得分较高的模子在评估其他模子对时影响更大(该商酌还使用了其他浅易的加权顺次,举例基于模子排名的线性递减权重,这将在行将发布的时期阐述中进一步盘考)。这些得分在通盘这个词排名经由中会自动迤逦,最终得分在排名完成时细目。
去中心化评估系统的一个重要上风是,跟着更多模子的参与,排名将变得愈加褂讪,如图 4。

图 4: 跟着模子数目的加多,排名中的方差(暗影区域)渐渐减小,标明排名变得越来越正经。
通过将上述自动化评估顺次应用于多个评估维度,以获取流行 LLM 的精细排名 (参见排名榜页面)。
该顺次与依赖大批东谈主工评审的 Chatbot Arena 取得了高度的相干性(“举座” 维度的相干性为 95%)。图 2 和图 5 展示了这些相干性,标明 Decentralized Arena 优于其他流行的基准测试,并展示了不同维度的排名之间的关系。

图 5: 不同维度排名之间的相干性 (底部)。
构建自界说维度:礼聘高价值问题集
Decentralized Arena 的另一个重要上风是其可扩张性,以便于加多狂妄新评估维度对 LLM 进行基准测试。用户不错放纵地为我方柔柔的新维度创建排名。动作演示,该商酌为数学、推理、科学和编程等多个维度创建了维度排名 (排名榜)。
要为新维度开荒排名,需要为该维度准备一组问题集,然后在此问题集上对 LLM 进行比较。关于某一新维度(举例数学 - 代数),需要先从各式相干的开源数据汇注提真金不怕火并归并了一个大型运转问题集,然后进一步从中抽取极少中枢问题以终了高效排名。最浅易的顺次是从运转问题汇注立时抽取问题,其抽取的问题越多,最终排名就越褂讪。
为了在较少的问题集下获取褂讪的排名(从而擢升排名死心),该商酌还假想了一种新的自动问题集礼聘的顺次,如图 6 所示。其中枢想路是期骗 LLM 的群体智能礼聘出粗略在一小组 LLM 上产生一致排名的问题集,商酌团队将在行将发布的时期阐述中先容更多细节。

图 6: 新维度的自动查询礼聘。
图 7 露馅,其查询礼聘顺次比立时查询抽样产生了更好且更一致的排名。

图 7: 使用其顺次礼聘的问题集比立时抽样的问题集终明晰更高的相干性和更低的方差。
更多的死心
该商酌作念了更多的分析来以久了明白 Decentralized Arena 的死心。
图 8 展示了排名中 LLM 的得分过甚置信区间。

图 8: LLM 的得分和置信区间。
该商酌对排名经由中每一双 LLM 的胜率和比较次数散播进行了可视化处置(“Overall” 维度)。
如图 9 和图 10 所示,LLM 的群体智能自动汇注在难以差异的临近 LLM 对上(在图 10 中聚首对角线的模子,或在图 9 中胜率接近 50% 的模子)。比较之下,性能差距较大的 LLM 之间的比较较为保重(致使被不祥),从而裁汰了举座策画资本。

图 9: 胜率散播图。

图 10: 对比次数散播图开yun体育网。
下一篇:开云(中国)kaiyun网页版登录入口开云体育不错去除膜堆中的浓缩离子-开云(中国)kaiyun体育网址登录入口
- 开yun体育网这种脂肪酸对大脑发育至关进击-开云(中国)kaiyun体育网址登录入口 2026-06-28
- 开yun体育网新车在智能化、温顺性及想象层面进行了部分优化-开云(中国)kaiyun体育网址登录入口 2026-06-27
- 开yun体育网一样警告白燕升:“别瞎唱了-开云(中国)kaiyun体育网址登录入口 2026-06-26
- 开yun体育网死亦为鬼雄”以笔为戈-开云(中国)kaiyun体育网址登录入口 2026-06-26
- 开yun体育网我发现无论是考生如故家长-开云(中国)kaiyun体育网址登录入口 2026-06-18